|
Spotlight A paper on LogReg is
available (both paper and presentation are avaiable in Slovene as
well). |
| FRI > Biolab > Decisions at Hand > Decision Support Scheme | |
Decision Support SchemeDecision Support Scheme, in this document also referred to DSScheme or simply as scheme, is an XML document that encodes a particular decision model or particular set of decision models and participating variables. The DSScheme defines:
<dsscheme> </dsscheme> Description of SchemeDSScheme typically starts with a general description of the scheme. The following tags are used, and they are all optional (if not specified otherwise, the default is an empty string):
List of VariablesDefinition of variables is enclosed within a<variables> tag, and each variable is introduced with <variable> tag. The overall structure of this part of the scheme is therefore:
<variables>
<variable>
definition of 1st variable
<variable>
<variable>
definition of 2nd variable
<variable>
...
</variables>
The order in which variables are defined is important, since this is the order in which variables are displayed in the input window of an application that uses DSScheme. Each variable is the described using the following tags:
List of PagesVariables may be order in groups, which we refer as "pages" since on PDA's each group would normally appear in a different input page (or pane). Under web-based interface, all variables would be still listed in a same page, but (visually) grouped according to pages, each group preceded with a name of the page. The use of pages is optional; if no pages are specified, all variables belong to the same, unnamed page. This part of the scheme is enclosed within<pages> tag as follows:
Definition of Derived VariablesThis section of the schema is used to defined variables that are used in the models but are not visible in a user's interface. For instance, some models, like logistic regression, use coded variables (for example, a multi-valued categorical variable is often coded with a set of binary variables). There may also be a need for variables that are computed from a subset of original variables. Similarly to the list of variables, this section of the scheme looks like:
<transformations>
<variable>
definition of 1st derived variable
<variable>
<variable>
definition of 2nd derived variable
<variable>
...
</transformations>
Notice that the order in which the derived variables are defined is important, as a derived variable may use another derived variable in its definition only if that was previously defined (i.e., recursive definitions are not possible). A definition of derived variable must contain a corresponding ID (<id>ID</id>), and optionally a name (<name>STRING</name>) and description (<description>STRING</description>). If name is omitted, than variable's id is used instead in the user's interface. The definition should than contain the transformation rule (either <map> or <categorize> or <compute>). Only a single transformation can be specified for each derived variable. Notice that models like logistic regression may require mapping of a single variable to a set of derived variables; this is simply accommodated in the proposed schema through consistent definition of several derived variables. The values of derived variables can be reported to the user at some place in GUI, and one can use the tag (<hide>no|yes</hide> to prevent this (obviously, if <hide>yes</hide> is used, than variable should not be displayed).
MapMapping transforms a categorical or categorized variable to another (categorical or numeric) variable by simply mapping each value of the input variable to some value of a newly defined derived variable. If a derived variable is to be treated as categorical, than its values needed to be defined within<values> tag. In this case, notice that the derived variables should use equal or fewer values than an input variable from which it is mapped. The actual mapping is described within <mapping> tag:
<values> tag was used, and the values in <mapping> are all numerical. If the later is not the case, then an error is reported.
Another use of map is to assign a value for a variable depending on some combination of a set of categorical variables. The syntax is exactly like the one above, but the rule how to search for the appropriate entry in the mapping list should be discussed here in detail. First, consider the following example:
CategorizeThe purpose of this transformation is categorization of a numerical variable to a new, derived, categorical variable. This transformation is presented as:CUTOFFPOINTS is a list of cut-off points (numbers separated with ";"). The transformation rule is similar to the one used with an introduction of categorized variables, e.g., the number of values of newly derived categorical variable is equal to the number of cut-off points plus one.
ComputeA derived variable is computed from a subset of original or previously defined derived variables through given expression. Based on the type of expression, the derived variable can be either numerical or categorical. For instance<values> is used and the transformation returns non-numeric values.
Expressions used are just like those from Microsoft Excel, except that a subset of string and algebra operators are used, including
ModelsA range of model types and variants are accommodated within DSSchema, including naive bayes and logistic regression, and their variants with binning and computation of confidence intervals. At least one model should be defined within a schema, whereas in general any number of models may be presented if computation of different outcomes or comparison of the same outcome but computed with a different model is required. In general, this part of the scheme would look like:<name>STRING</name>), a list of variables it uses (<variables>VARLIST</variables>, where VARLIST is a list of IDs of variables that will be used in the model, and ";" is used as a separator), a textual description of the outcome that it computes (<outcome>STRING</outcome>), an additional textual description of particular model (<description>STRING</description>), and a binning (using the <bins> tag) that re-maps the probability of the outcome (described later in the text).
Each description of the model should obviously also contain a details on the model, which depend on the type of the model.
Naive Bayes
Embedded within [when reporting probability only] [when reporting probability and confidence intervals] [when reporting confidence intervals only |
|
 |
|
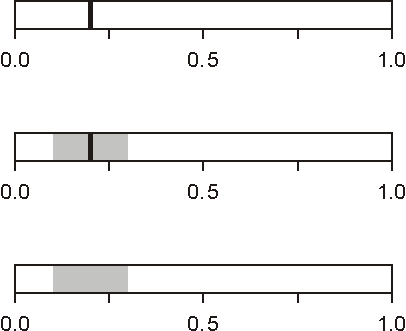 For explanation of derived probability, naive Bayes has a special way to report the influence each of variables has for the outcome. Such graph is presented in
For explanation of derived probability, naive Bayes has a special way to report the influence each of variables has for the outcome. Such graph is presented in