| FRI > Biolab > Supplements | |||||||||
Data set name: leukemiaOriginal data set (Golub et al.) Data set for Orange
Platform: Affymetrix HuGeneFL array
Number of samples: 72 Note: From the originally measured 6817 probe sets we removed genes that were not present (P) in at least one sample
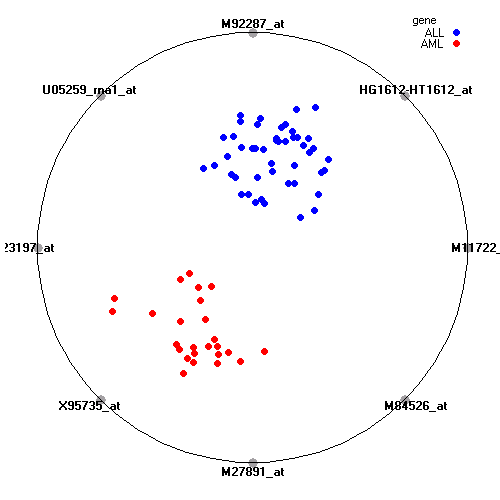
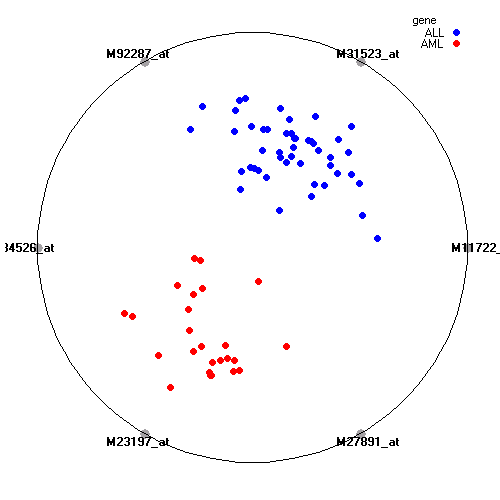
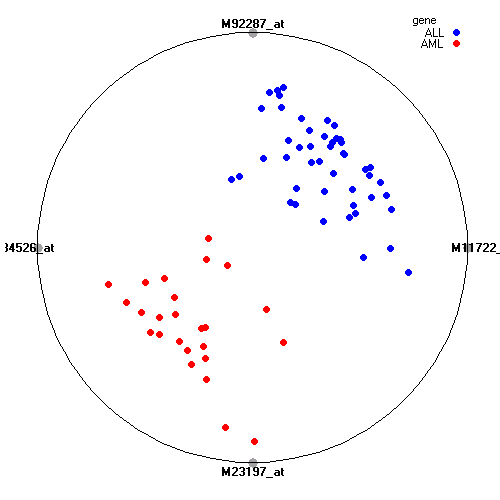
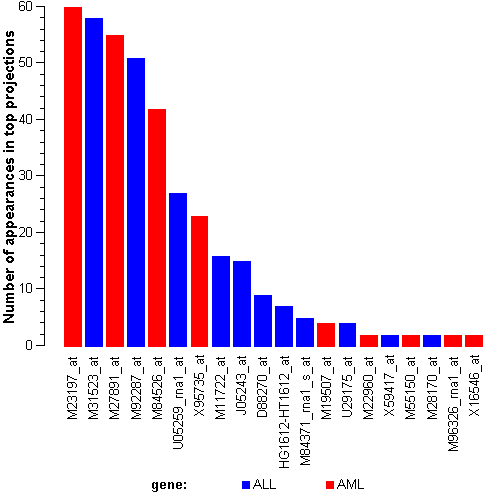
Attribute rankingFollowing is the histogram of genes showing how often are they present in one of the top 100 radviz visualizations with 8 attributes.
|
|||||||||
 |
|||||||||